


سلام به همه بچههای علاقمند به کامپیوتر و برنامهنویسی و هوش مصنوعی. همانطور که میدونین روز به روز دنیای هوش مصنوعی داره وسیعتر میشه و به حوزه مختلف از علوم راه یافته است. ما تصمیم داریم هر هفته با یک مقاله در این حوزه، شمارو با رویداد های دنیای هوش مصنوعی آشنا کنیم و مهمتر اینکه ریاضیات این حوزه رو با ساده سازی به شما دانش آموزان عزیز کانونی توضیح بدیم. در نهایت بتونیم قدم به قدم به کد نویسی در محیط پایتون برای مسئله های جذاب هوش مصنوعی برسیم. پیشنهاد میکنم هر هفته مارو با یک مقاله در این حوزه دنبال کنید.
روال همیشگیمون اینه که هر هفته جدید یه مطلب جدید براتون بیاریم. این هفته هم مستثنی نیست و قراره یه سفر کوتاه علمی با هم داشته باشیم. پس کمربندهارو خوب ببندید و حواسها رو جمع کنید که احتمالا یه عدهتون بعد خوندن این مطلب شغل آیندهتون رو انتخاب میکنید!

یکی از بخشهای اولیه و مهم یادگیری ماشین (Machine learning) پیش-پردازش داده یا همون pre-processing data است. یادگیری ماشین حوزهایه که در اون متخصصا سعی میکنن ماشینها رو هوشمندتر از قبل بکنن به طوری که دست آخر یه ماشین بتونه مثل مغز یک انسان اطلاعات رو پردازش بکنه. خب مثل همه چیزا این کار یه سری مراحل خاص خودش داره که همونطور که گفتیم از مراحل اولیه اون پیش-پردازش کردن داده است. حالا یعنی چی که دادهها رو از قبل پردازش بکنیم. یعنی این که قبل از اینکه دادههامون رو به دست الگریتمهای یادگیری ماشین بسپریم، یه دستی باید به سر و شکلشون بکشیم یا نه؟! البته که باید. اینجا همونجایی که دادهها باید پیش از فرستاده شدن درون الگریتمها پردازش بشن.
حالا چرا pre-processing data اینهمه مهمه؟ چون دقت کارمون رو بالا میبره. چون داده یه مشت اطلاعات درهمبرهمه که حتی بعضی وقتا میتونه اطلاعات گمراهکننده و غلط بهمون بده.
دو روش (Method) برای این نوع از پردازش وجود داره:
- انتخاب یه بخش (Feature selection)
- استخراج یه بخش (Feature extraction)
اگه دادههامون رو از فیلتر این دو روش رد بکنیم، دقت مدلمون رو بالاتر خواهیم برد.
انتخاب یه بخش
در این روش بخشهای از داده رو، یا به بیان دیگه اون دادههای رو انتخاب میکنیم که به دردمون میخوره و بقیه رو کنار میذاریم. مثلاً فرض کنید میخواییم بفهمیم که یه ماشین چند کیلومتر کار کرده. برای این کار یه مشت اطلاعات در اختیار ما میذارن. از ظرفیت موتور ماشین بگیر تا ماکسیمم سرعت ماشین تا رنگ اون. طبیعیه که ما فقط به ظرفیت موتور و سرعت ماشین نیاز داریم و رنگ اون به دردمون نمیخوره. پس با این کار دادههای به درد نخور رو کنار گذاشتیم.

استخراج یه بخش
- تصویر
با این متد Mبخش دادهمون تبدیل میشه به Nبخش. تعداد بخشهای یه داده قبل از این عملیات ممکنه بیشتر از وقتی باشه که این متد رو روش اعمال کردیم. همچنین میتونن کمتر و مساوی هم باشن. از اونجایی که متد حاضر یه حوزه وسیعی رو شامل میشه ما فقط بخش مهمشو مرور میکنیم.
فرض کنید داده شما یه عکسه. هر عکس متشکل از هزاران پیکسل است. هر پیکسل یه بخش یا همون Feature هستش که امکان داره الگریتم مورد نظر شما ظرفیت اینهمه بخش رو نداشته باشه. شما تو این روش میتونید مثلاً رنگهای عکس رو با «نمودار رنگ» استخراج کنید یا تعداد پیکسلهاشو بکشید بیرون و ... .

- متن (Text)
استخراج همچنین تو متن هم کاربرد زیادی داره. معروفترین متدهای استخراج داده از متن عبارتند از:
- Count Vectorizer
- TFIDF Vectorizer
- Word Embeddings
- One-hot Vector
- Bag of Words
در واقع سر و کله زدن با دادههای متنی بخش مهمی از آنالیز داده حساب میشه. یه نمونه از استخراج بخشهای از متن میتونه این باشه. فرض کنید دو ستون در یک جدول داریم. یه ستونش یه سری رشته (String) است و ستون دیگه شامل اعداد اعشاری میشه.

الگریتم هیچ وقت نمیتونه string شما رو تشخیص بده. اینجا باز میتونیم از pre-processing کمک بگیریم. یعنی اسم کشور رو به صورت یه بخش اضافه میکنیم و از عدد اعشاری (Boolean value) استفاده میکنیم تا به کشور مورد نظر اشاره کنیم. این روش شبیه همون Count vectorizer و One-hot vectorاست.

خب حالا اگه تعداد بخشهای یه داده انقدی رفت بالا که سرسام آور بشه چی؟ از روش کاستِ ابعاد یا Dimensionality Reduction استفاده میکنیم. این روش بخش مهمی از Data pre-processing است و جایی بیشترین کاربرد رو داره که دادههای همینطور در حال افزایش هستن. وقتی پردازش سختتر میشه که ابعاد بخشهای و عناصر یک داده بیشتتر بشه. متدهای مورد استفاده در این حوزه عبارتند از:
- Principal Component Analysis (PCA)
- Singular Value Decomposition (SVD)
که این آخریه ابعاد یه داده رو کاهش میده.
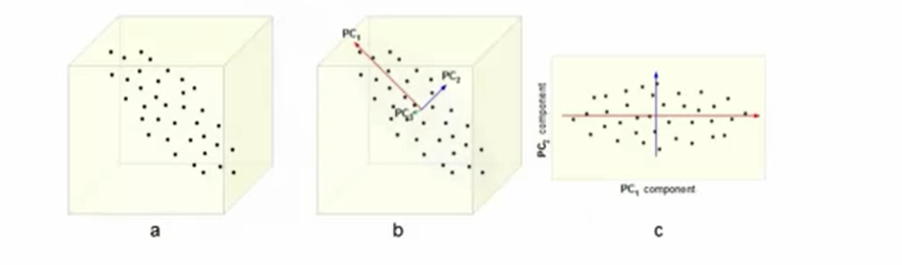
کاست بعد همچنین تو حوزه تجسم داده یا به بیان سادهتر در اینکه داده رو به تصویر تبدیل کنیم میتونه کمکمون بکنه.
بعد از اینکه همه این کارا رو کردیم، دیگه وقتشه دادههامون رو وارد الگریتمی تو یادگیری ماشین کنیم.

منابع
Data Preprocessing Steps for Machine Learning & Data analytics - YouTube
دوستان عزیزم؛ برای ارتباط با برترها و رزرو پشتیبان ویژه پیج کانون برترها را دنبال کنید.
همچنین میتوانید با شماره 0218451 داخلی 3123 تماس بگیرید.

